Data Deep Dive
Mexico Covid-19 Line List
Data up to August 25th, 2021
| Completeness * | |
|---|---|
| FECHA_INGRESO (Admission Date) | 100% |
| ID_REGISTRO (Registration ID) | 100% |
| FECHA_SINTOMAS (Date of Symptom Onset) | 100% |
| MUNICIPIO_RES (Residential Municipality) | 99.998% |
| EDAD (Age) | 100% |
| NACIONALIDAD (Nationality) | 100% |
| UTI (ICU admission) | 100% |
*as of 25/08/2021;
In the following case-study we take a deep-dive into COVID-19 line-list data from Mexico, one of the >130 countries included in the Global.health platform. The case-study covers information about provenance of the data, data transformations to fit the Global.health schema, and key characteristics and limitations of the data. While only addressing one country, the design of Global.health lets users quickly ask similar questions about any country included in the platform. We will discuss how users can conduct such an investigation on their own. Stay tuned for more of these data deep dives coming up. Here are other examples for Brazil, Peru, and Colombia.
Similar to many other countries in the Americas, the Mexico line-list data has high completeness of key clinical dates, such as date of confirmation, date of symptom onset, date of hospitalisation, date of outcome, and includes information about results of diagnostic tests. In addition, a number of fields provide information available on patients comorbidities, which is useful for understanding the disease burden of COVID-19 across different cross-sections of the population. Furthermore, the vast majority of cases are geolocated to good resolution (Administrative level 2, municipality level), and very few cases are missing geolocation or key dates. However, it should be noted that an excess mortality study has found the Mexico line-list to be under-reporting deaths by ⅓ to ½, as discussed here.
01.
What is the provenance of the data?
Following a federal decree on open health data in 2015, the General Directorate of Epidemiology of the Government of Mexico (Dirección General de Epidemiología) has been providing open data on vector-borne diseases, febrile exanthematic diseases, and annual morbidities since 2015. In 2020, COVID-19 line-list data was incorporated into this surveillance network. The line-list database is openly available through the Ministry of Health website as a single downloadable dataset.
In general, the COVID-19 case reporting in Mexico is fairly extensive, with a rich line-list dataset detailing demographics, clinical events, symptoms and patient comorbidities, which is updated daily. The values in descriptive fields (so not including dates and unique IDs) are encoded into categorical variables, each with a unique encoding, which makes the data dictionary essential to interpret the data. The first confirmed positive case in the line-list was on February 19, 2020.
02.
Where can I find the original data and how is the data transformed?
The line-list dataset records all suspected and confirmed cases of COVID-19, including suspected cases which subsequently received negative or invalidated tests. We filter the dataset to only include confirmed COVID-19 cases, by taking the subset of rows where ‘CLASIFICACION_FINAL’ has value 1, 2 or 3. These have the following definitions:
| Value | Label | Explanation |
|---|---|---|
|
1 |
CASO DE COVID-19 CONFIRMADO POR ASOCIACIÓN CLÍNICA EPIDEMIOLÓGICA
|
A case confirmed as positive ‘by association’. When the case is reported being a positive contact for COVID-19, but no test sample was taken or the test sample taken was invalid. |
|
2 |
CASO DE COVID-19 CONFIRMADO POR COMITÉ DE DICTAMINACIÓN
|
‘Confirmed by ruling’ applies to deaths where no test sample was taken, or where the test sample taken was invalid. |
|
3 |
CASO DE SARS-COV-2 CONFIRMADO |
A positive COVID-19 confirmed by an antigen or laboratory test.
|
Table 1: The possible values of the ‘CLASIFICACION_FINAL’ field, alongside their label and an explanation of their meaning.
We take the registration ID (‘ID_REGISTRO’) of each row as the universally unique identifier (UUID) assigned to that case in our database, which allows us to look up each case in isolation and de-duplicate cases as new data is ingested each day.
Datasets occasionally contain information that does not fit our current schema, but nevertheless seems pertinent to capture. In these cases we add this information into the plain text ‘Notes’ field. For example, the Mexico line-list records a person’s smoking status, as well as whether a person is pregnant or immuno-suppressed; our current database schema does not contain these fields, so we simply translate these notes into english and add this information in plain text into the ‘Notes’ field. We are constantly adapting our database schema to best capture the rich information contained in global COVID-19 line-list datasets, so watch this space for updates to the G.h schema.
The geographical location of a case is vital for building spatial epidemiological models of COVID-19 infection. The Mexico line-list provides the State and Municipality (Admin2) of each case.
We geocode cases within Mexico by combining the State and Municipality information where present. In a small number of cases Municipality is absent, in which case we geocode cases to state level; if both State and Municipality are absent cases are simply geocoded to Mexico. We also use a lookup table to convert municipality codes to coordinates, which can be found in the Mexico parser directory. The lookup table was taken from here.
03.
How complete is the data compared to aggregated data sources?
The World Health Organisation aggregate count of COVID-19 cases in Mexico on August 25th, 2021 was 3,231,616. Taking all cases confirmed as positive by one of the three methods above (ie CLASIFICACION_FINAL == {1, 2, 3}), the Mexico linelist contained 3,249,878 positive cases on this date.
04.
Key characteristics and limitations of this database:
There are 42 fields in the raw dataset, 36 of which are categorical variables on demographics, clinical events, symptoms and diagnostic testing. The G.h parser uses the data dictionary to decode these 36 categorical variables and convert them into a suitable format to fit our database schema. The data dictionary is not fully complete, and a mapping of certain numbers to their respective category is not always explicit, but can be inferred with relative confidence. For example, no mapping of category codes are provided for whether a case is pregnant (‘EMBARAZO’), a migrant (‘MIGRANTE’), or their smoking habit (‘TABAQUISMO’). In general in this dataset, binary variables have: 1 == ‘Yes’, 2 == ‘No’, and any number that starts with a 9 such as 97, 99, or indeed 999, means unknown or NA.
Like the Brazil hospitalization line-list data, the Mexico line-list includes relatively rich documentation of individual patient’s health status and comorbidities. Binary variables are documented for: diabetes, asthma, COPD, hypertension, obesity, immunosuppression, chronic kidney failure and ‘other comorbidities’. The relative frequency of positive values for these binary variables are shown in Figure 1. Additionally, binary variables indicate whether a patient was pregnant, and whether they smoked. Clinical events are also well documented, such as whether a COVID-19 patient was intubated or suffered pneumonia, as well as the dates of symptom onset and date of death.
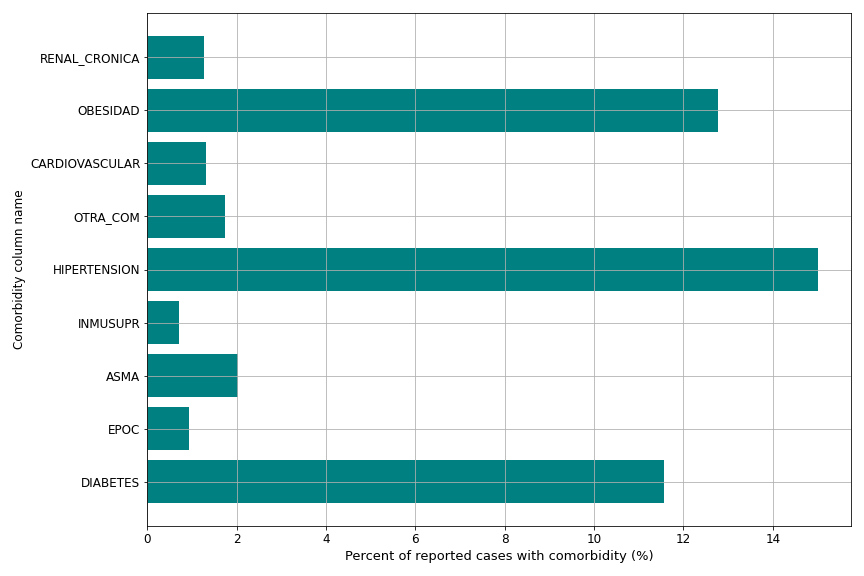
Figure 1: The percent of linelist cases with reported comorbidities.
In addition to rich clinical data, the Mexico dataset also provides additional information on testing. Two fields TOMA_MUESTRA_ANTIGENO and TOMA_MUESTRA_LAB indicate whether each case underwent an antigen or laboratory (PCR) test respectively, and RESULTADO_ANTIGENO and RESULTADO_LAB indicate the results of these tests, including whether they failed (“RESULTADO NO ADECUADO”). From this information we can see that as of 25/08/2021, 58.5% of the 3,249,878 positive cases underwent a laboratory COVID-19 test (i.e., Polymerase Chain Reaction test), and 43.9% tested positive with an antigen test.
Finally the Mexico dataset contains several informative fields detailing case origin and nationality. PAIS_NACIONALIDAD gives the nationality of each case and shows that 99.63% of cases in the line-list were Mexicans. PAIS_ORIGEN is a useful field that documents the country which the case travelled from, which we can use to construct a travel history. Unfortunately the vast majority of cases have unknown country of origin (99.93% have PAIS_ORIGEN == 97). The 2375 cases on 25/08/2021 whose country of origin is known, as well as the distribution of the most frequent case nationalities, are shown below in Figure 2. The field MIGRANTE documents whether a case was a migrant or not, although in the vast majority of cases this field is left as NA (MIGRANTE == 99). There is even a field that documents whether or not each case speaks an indigenous language: ‘HABLA_LENGUA_INDIG’ is True for 20,036 of the ~3.25 million cases.
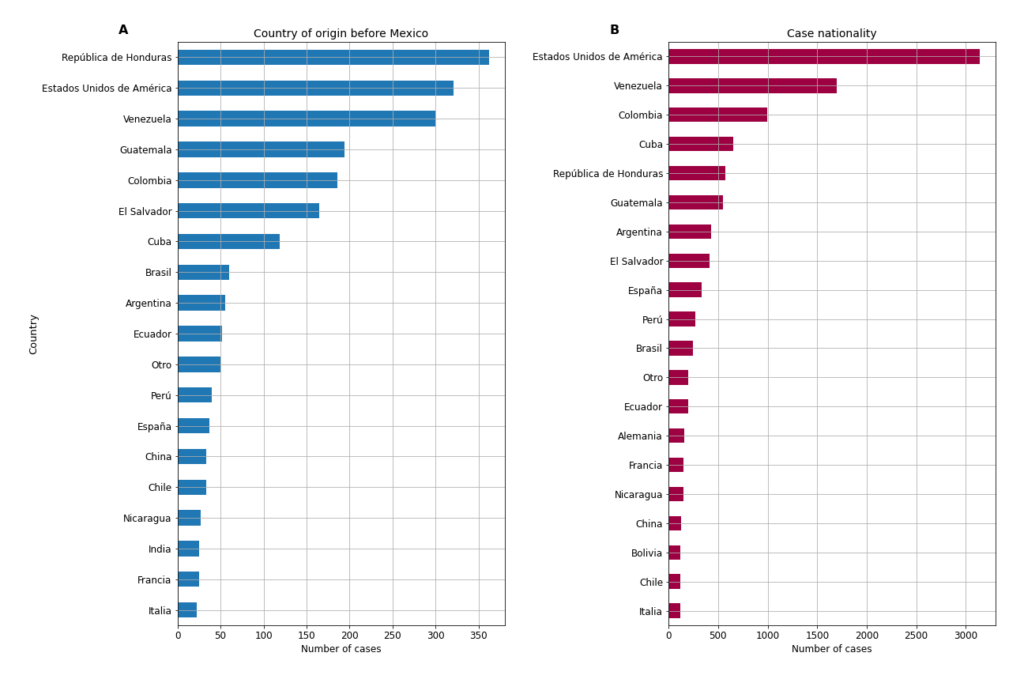
Figure 2: The 20 most frequent (A) countries of origin and (B) nationalities (excluding Mexico).
05.
How to filter, view, and download this data:
To access the most up to date data described above please follow this link. You can also access a visualisation of these data on our Map application.
Signature & Contact

Felix Jackson
Researcher and DPhil Student,
Computer Science Department,
University of Oxford
on behalf of the Global.health team